
Hoy en día tenemos muchas Inteligencias Artificiales de generación de imágenes disponibles. Incluso podemos crear la nuestra y mejorarla para adaptarla a nuestras necesidades. ¿Quieres aprender a hacerlo? ¡Vamos a ello!
Índice de contenidos
Stable Diffusion
Stable Diffusion es un modelo generativo de imágenes basado en inteligencia artificial diseñado para crear imágenes coherentes y detalladas a partir de descripciones textuales (prompts). Fue desarrollado por Stability AI y es ampliamente utilizado debido a su arquitectura eficiente y Open Source.
Cómo funciona
Stable Diffusion combina tres componentes principales que trabajan juntos para generar imágenes:
Autoencoder
El autoencoder comprime las imágenes en un espacio latente más manejable. Este proceso permite que el modelo trabaje con menos información, mejorando la eficiencia computacional.
U-Net
El U-Net es una red neuronal convolucional que toma imágenes con ruido y las convierte progresivamente en imágenes limpias basadas en la descripción textual proporcionada.
Text Encoder
El Text Encoder transforma el texto en un espacio de características comprensible para el modelo. Este proceso traduce las palabras a un formato que el modelo puede interpretar adecuadamente.
Generación de imágenes con Diffusers Library
Requisitos
Estos procesos tienen un coste computacional bastante alto, por lo que si no dispones de un sistema con GPU potente, es recomendable usar Google Collab para obtener una mayor eficiencia. ¡Pero cuidado! La librería diffusers de HuggingFace es gratuita, pero si usas servicios en la nube como Google Colab, puede haber costes asociados.
pip install diffusers
pip install invisible-watermark transformers accelerate safetensorsVersiones
Los modelos más populares son:
- Stable Diffusion v1.5
- Stable Diffusion XL
- Flux.1 dev
Generación de imagen
Usamos cuda para aprovechar la potencia de la GPU para un mayor rendimiento. En este ejemplo de código, solamente tendrás que cambiar el prompt por el texto que elijas y lanzar el programa.
import torch
from diffusers import StableDiffusionPipeline
from PIL import Image
# Cargamos el modelo
pipeline = StableDiffusionPipeline.from_pretrained(
"stabilityai/stable-diffusion-2-1", torch_dtype=torch.float16
)
pipeline = pipeline.to('cuda')
prompt = "A cat on a box"
image = pipeline(prompt=prompt).images[0]
Cuando ejecutas este código por primera vez, se instalarán dependencias y modelos de hasta 5GB, por lo que tardará más. Esto solo ocurre en la primera ejecución.
Generación de imágenes con la API de inferencia de HuggingFace
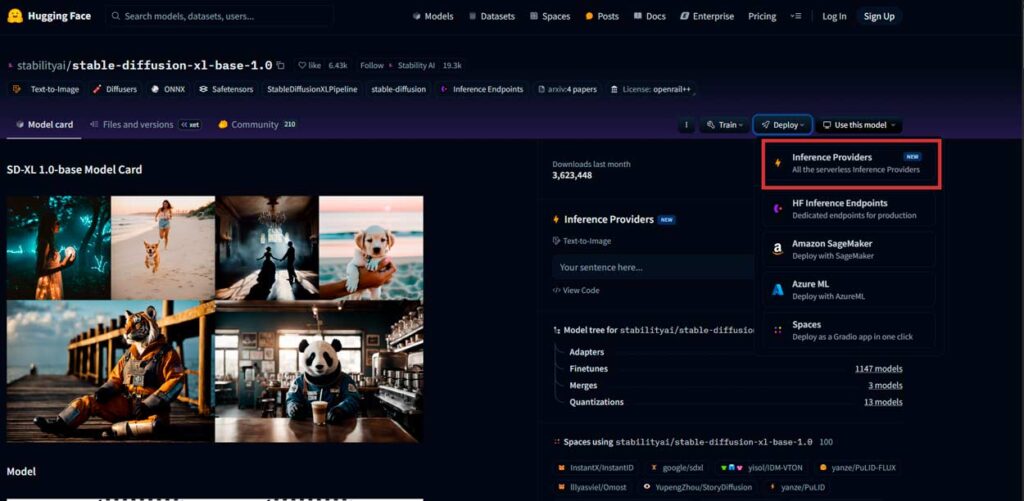
Otra opción es usar la API de Inference de HuggingFace. Esto permite utilizar el modelo de Stable Diffusion sin tener que descargarlo localmente.
Para ello debemos ir a la página de modelo y seleccionar la opcion Deploy. Aquí verás la opción Inference API, esto te generará la URL que necesitas para tu IA de generación de imágenes. La implementaremos de la siguiente manera:
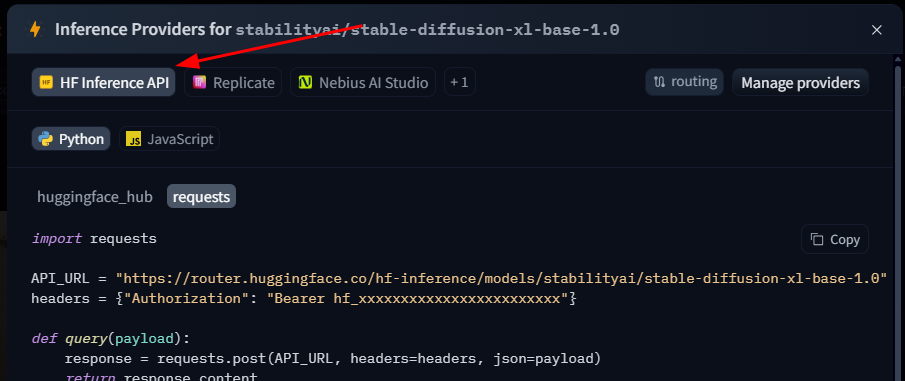
import requests
import io
from PIL import Image
from IPython.display import display
# Aquí la URL que hemos obtenido
API_URL = "https://api-inference.huggingface.co/models/stabilityai/stable-diffusion-xl-base-1.0"
headers = {"Authorization": "Bearer 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"}
def query(payload):
response = requests.post(API_URL, headers=headers, json=payload)
return response.content
image_bytes = query({
"inputs": "A cat on a box",
})
# Convertimos la imagen
image = Image.open(io.BytesIO(image_bytes))
display(image)Mejorar el prompt con un modelo de generación de texto
Muchas Inteligencias Artificiales generativas de imágenes, como por ejemplo LeonardoAi, alteran el texto que ponemos para detallar más y facilitar el trabajo al modelo. Nosotros también podemos implementar esto de manera muy sencilla. En este caso vamos a importar el modelo de generación de texto gpt2 de OpenAI.
gpt2 = pipeline("text-generation", model="openai-community/gpt2")
text = "A cat on a box"
generated = gpt2(text)
pipe = StableDiffusionPipeline.from_pretrained("stable-diffusion-v1-5/stable-diffusion-v1-5")
prompt = generated[0]['generated_text']
image = pipe(prompt).images[0]
plt.imshow(image)
plt.title(prompt)
plt.axis('off')
plt.show()En este caso vemos que el texto que le pasa a el modelo es bastante distinto del que hemos escrito inicialmente.
Mejora de resultados: Fine Tuning
Además de ajustar el prompt para acercarnos al resultado que queremos, también podemos «afinar» el modelo. A esto se lo denomina Fine tuning. Es un proceso que puede llevar horas, dependiendo de cuanto lo queramos mejorar.
from transformers import AutoModelForCausalLM, AutoTokenizer, TextDataset, DataCollatorForLanguageModeling, Trainer, TrainingArguments, pipeline
from diffusers import StableDiffusionPipeline
import matplotlib.pyplot as plt
import torch
# Cargar el modelo y el tokenizador
model_name = 'openai-community/gpt2'
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(model_name)
# Crear el dataset de fine-tuning
train_dataset = TextDataset(
tokenizer=tokenizer,
file_path='your_dataset.txt', # Archivo con el texto para ajustar
block_size=128
)
data_collator = DataCollatorForLanguageModeling(tokenizer=tokenizer, mlm=False)
# Configuración del entrenamiento
training_args = TrainingArguments(
output_dir='./finetuned_model',
overwrite_output_dir=True,
num_train_epochs=10,
per_device_train_batch_size=2,
save_steps=500,
save_total_limit=2
)
# Entrenador
trainer = Trainer(
model=model,
args=training_args,
data_collator=data_collator,
train_dataset=train_dataset
)
# Entrenar el modelo
trainer.train()
# Guardar el modelo ajustado
trainer.save_model('./finetuned_model')
def generate_text(prompt):
generator = pipeline('text-generation', model='./finetuned_model', tokenizer=tokenizer)
generated = generator(prompt, max_length=50, num_return_sequences=1)
return generated[0]['generated_text']
# Generar texto con el modelo ajustado
prompt_text = 'A cat on a box'
generated_text = generate_text(prompt_text)
# Cargar Stable Diffusion
pipe = StableDiffusionPipeline.from_pretrained('stable-diffusion-v1-5/stable-diffusion-v1-5').to('cuda')
# Generar imagen con el prompt generado
image = pipe(generated_text).images[0]
# Mostrar la imagen generada
plt.imshow(image)
plt.title(generated_text)
plt.axis('off')
plt.show()
Resumiendo
Crear una IA generativa de imágenes puede ser un proceso fácil y eficiente gracias a herramientas como Stable Diffusion. Ahora es tu turno. ¿Qué implementación prefieres? ¡Te leemos en comentarios!




Deja una respuesta
Tu dirección de correo electrónico no será publicada. Los campos obligatorios están marcados con *