
En este artículo, crearás tu primera Inteligencia Artificial de detección, tanto para imágenes como para vídeos. ¿Suena difícil? Con los modelos preentrenados que ofrecen empresas como Ultralytics YOLO, es muy sencillo, y nos puede servir de iniciación a la IA para detección. ¡Vamos a ello!
Índice de contenidos
¿Qué es YOLO?
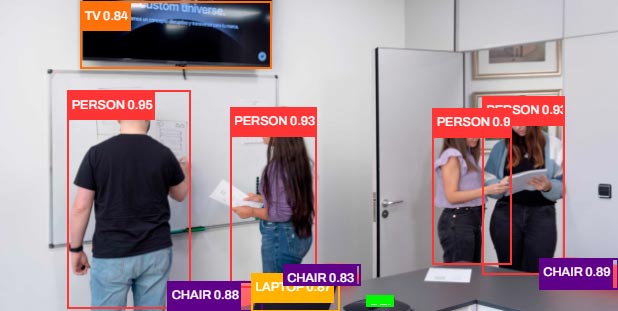
YOLO es una serie de modelos desarrollada por Ultralyitics para la detección y segmentación de imágenes en tiempo real. Esta tecnología es Open Source y está publicada en GitHub. YOLO destaca por ser un detector de un solo paso que realiza predicciones en imágenes completas con una única pasada a través de la red neuronal, lo que lo hace extremadamente rápido y eficiente.
¿Por qué YOLO?
YOLO destaca frente a otros métodos de detección de objetos por su eficiencia en velocidad y precisión. Esto se debe a su enfoque basado en detección de un solo paso en lugar de sistemas de múltiples pasos que realizan propuestas de regiones, clasificación y refinamiento por separado.
Ventajas de YOLO:
- Alta velocidad de procesamiento, perfecto para aplicaciones en tiempo real.
- Buena precisión en la detección de objetos, incluso con objetos pequeños.
- Facilidad de uso y entrenamiento gracias a la implementación de Ultralytics.
- Soporte activo y mejorado constantemente por la comunidad Open Source.
Desventajas de YOLO:
- Puede tener dificultades con la detección de objetos que se solapan.
- Menor precisión que otros detectores como Faster R-CNN en tareas específicas.
Cómo funciona
YOLO divide una imagen de entrada en una cuadrícula de tamaño. Cada celda de la cuadrícula es responsable de predecir un número fijo de cajas delimitadoras (bounding boxes) y sus correspondientes puntuaciones de confianza. La puntuación refleja cuán seguro está el modelo de que la caja contiene un objeto y cuán precisa es la predicción.
Cada predicción consiste en:
- Coordenadas de la caja delimitadora .
- Puntuación de confianza.
- Clasificación del objeto detectado (si se aplica clasificación).
YOLO utiliza una única red neuronal convolucional (CNN) que procesa la imagen completa en una sola pasada. Esta CNN tiene múltiples capas convolucionales seguidas de capas completamente conectadas que producen la salida final con todas las predicciones.
Pérdida (Loss Function): La función de pérdida combina varios términos:
- Error de localización (coordenadas de la caja).
- Error de confianza (diferencia entre la confianza predicha y la realidad).
- Error de clasificación (predicciones incorrectas de la clase).

Aplicaciones
La detección de objetos con IA tiene muchas aplicaciones y muy diversas, aquí tienes unos ejemplos:
Vehículos autónomos: Detección de peatones, señales de tráfico y otros vehículos en tiempo real.
Seguridad: Monitoreo de cámaras de vigilancia para identificar intrusos o comportamientos sospechosos.
Sanidad: Segmentación de imágenes médicas, detección de anomalías y asistencia en diagnóstico.
Retail: Monitoreo de inventarios y análisis de comportamiento de clientes.
Ejemplo práctico
En este ejemplo, usaremos YOLOv11 para detección de objetos en imágenes y videos. Por cada modelo, tenemos varias versiones, más grandes o más pequeñas. Te animo a probar diferentes modelos con las mismas imágenes y comparar las diferencias.
Requisitos
- Es muy recomendable descargar anaconda y crear un entorno virtual
- Python 3.x
- OpenCV
- PyTorch
- El modelo YOLO que elijas, en este caso lo haremos con YOLOv11n
Instalación
pip install torch torchvision opencv-python
pip install ultralyticsCarga de modelo
from ultralytics import YOLO
# Carga del modelo elegido
model = YOLO('yolov11n.pt')Detección de objetos en imágenes
import cv2
# Cargamos la imagen con imread
image = cv2.imread('ruta_a_imagen.jpg')
# Se la pasamos al modelo para obtener los resultados
results = model(image)
# Llamamos a la función show para ver los resultados
results.show()Detección de objetos en vídeo
# Cargamos el vídeo con VideoCapture
cap = cv2.VideoCapture('ruta_al_video.mp4')
# Bucle para analizar cada frame del vídeo
while True:
ret, frame = cap.read()
if not ret:
break
# Detección de cada frame del vídeo
results = model(frame)
# Mostramos los resultados
results.show()
# Para poder salir de la detección
if cv2.waitKey(1) & 0xFF == ord('q'):
break
cap.release()
cv2.destroyAllWindows()Ejemplo real:
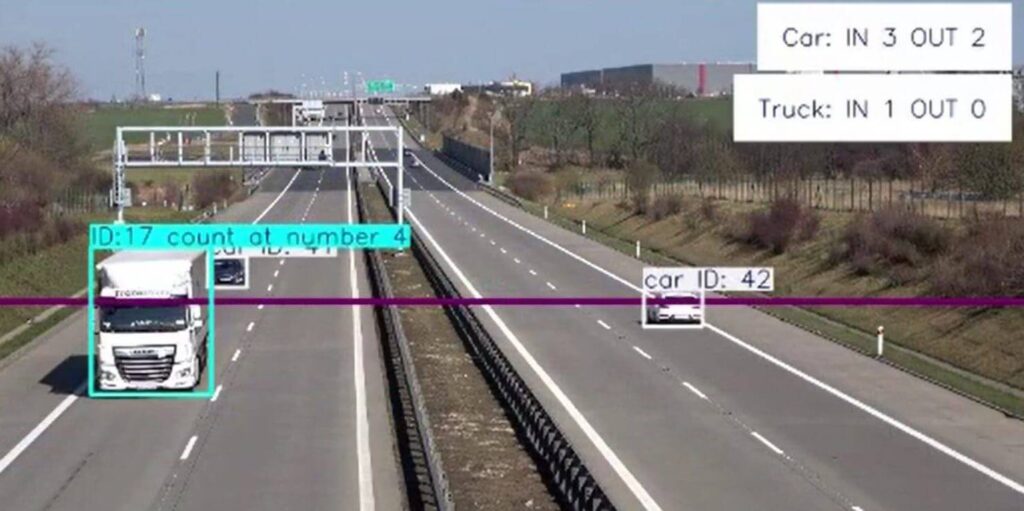
Si quieres probar con cosas más complejas, te recomendamos este vídeo. Aquí desarrollan una clase que te puede resultar útil para practicar, ObjectCounter. En el vídeo cuentan pasajeros en un autobús, pero esto lo podemos adaptar para contar lo que queramos. Probaremos a implementarla para contar cuántos coches y camiones pasan por una línea que nosotros establecemos.
cap = cv2.VideoCapture('vehicle-counting.mp4')
width = int(cap.get(cv2.CAP_PROP_FRAME_WIDTH))
height = int(cap.get(cv2.CAP_PROP_FRAME_HEIGHT))
print(f"Dimensiones del video: {width}x{height}")
cap.release()
def RGB(event, x, y, flags, param):
if event == cv2.EVENT_MOUSEMOVE:
point = [x, y]
print(f"Mouse moved to: {point}")
cap = cv2.VideoCapture('vehicle-counting.mp4')
region_points = [(0, 255), (1019, 255)]
counter = ObjectCounter(
region=region_points,
model="yolo11s.pt",
classes=[2, 7],
show_in=True,
show_out=True,
line_width=2,
)
cv2.namedWindow('RGB')
cv2.setMouseCallback('RGB', RGB)
count = 0
while True:
ret, frame = cap.read()
if not ret:
break
count += 1
if count % 2 != 0:
continue
frame = cv2.resize(frame, (1020, 500))
frame = counter.count(frame)
cv2.imshow("RGB", frame)
if cv2.waitKey(1) & 0xFF == ord("q"):
break
cap.release()
cv2.destroyAllWindows()
Conclusión
Como ves, hay muchos modelos preentrenados que puedes usar para adentrarte en el mundo de la Inteligencia artificial. Estos modelos facilitan mucho el trabajo y nos permiten enfocarnos en tareas concretas sin tener que hacer el largo proceso de entrenamiento de modelos, que eso da para otro par de artículos. ¿Te interesaría aprender a crear y entrenar tus propios modelos? ¡Te leemos en comentarios!




Deja una respuesta
Tu dirección de correo electrónico no será publicada. Los campos obligatorios están marcados con *